|
Hi Folks,
Problem: define a grammar for this simple data format: N item1 item2 ... itemN The first value in the input is a number N which specifies the number of following items. Ouch! That's not context-free. So basically you lose the entire context-free parsing toolkit. Stated another way, that problem requires a connection between syntax and semantics.
Alas, we enter the world of black art. Today the syntax-semantics connection is made by writing code. Let's illustrate how the connection is made in three different grammar languages: XML Schema 1.1, ANTLR, and BISON.
XML Schema 1.1 Use the ordinary context-free capabilities of XSD to define N and each item. Then embed XPath code into the XSD to constrain the number of items to N. Here it is:
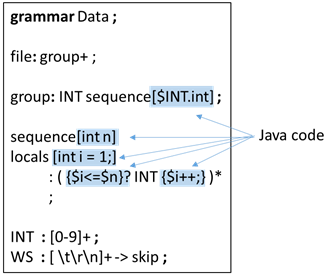
ANTLR Create parser and lexer rules. Embed Java code within the parser rules to constrain the number of items to N. Here it is:
BISON Proceed as with ANTLR, except instead of embedding Java code into the parser rules, embed C code.
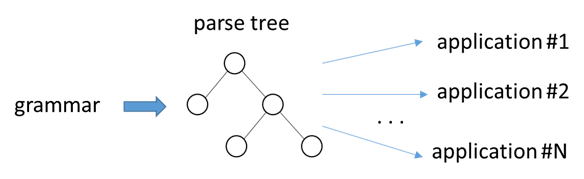
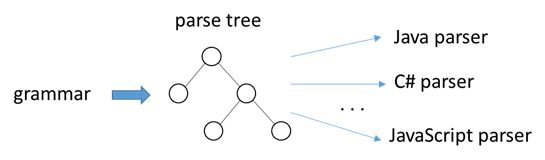
We want this: Reusable and Retargetable Grammars Reusable: multiple different applications can use the same parse tree.
Retargetable: multiple different languages can be generated from the same grammar.
The requirement for reusable and retargetable grammars is code-free grammars.
Want to Make an Impact on the World? Today it is nearly impossible to solve any non-trivial language recognition problem without embedding code into the grammar. In the example above we saw that we needed to embed XPath code in XML Schema, Java code in ANTRL, and C code in
BISON. And that was for a trivial problem.
Want to make a huge impact on the world? Fix this problem. No more embedded code in grammars.
Comments? /Roger |