Hi Folks,
I need to perform basic filtering on data, such as:
- Fuzz. Example: fuzz the telephone number 555-841-9087 to 555-841-0000
- Redact. Example: remove the word “secret” from the data
- Zero. Example: if the field labeled “amount” is empty, set it to 0
I need to create a language (or use some subset of an existing language) for expressing filter rules. The language must be usable by domain experts who aren’t necessarily computer savvy. The input data comes in a variety of different formats – some input data will be formatted as CSV, some input data will be formatted as vCard, some input data will be formatted as iCalendar, etc.. Input data may be text or binary. In other words, the input data is not necessarily XML.
As I see it, there are three approaches to expressing filter rules, as exemplified by XSLT, CSS, and DFDL.
XSLT Approach to Expressing Filter Rules
In this approach filter rules are expressed in a filter rules document. The language used to express filter rules must provide a navigation/path language for navigating through the data to identify the data item to be filtered. XSLT uses this approach. Here’s a graphic that illustrates the approach:
CSS Approach to Expressing Filter Rules
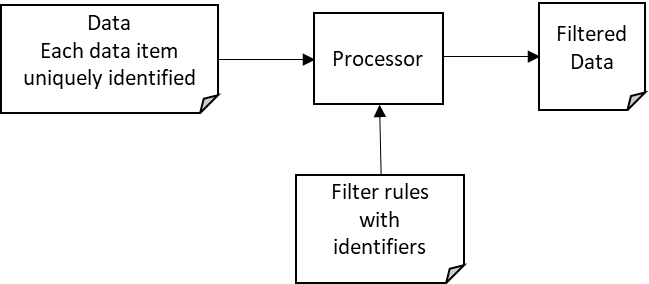
In this approach filter rules are expressed in a filter rules document. Each data item in the input data has a unique identifier. Each filter rule specifies a unique identifier and the filter rule. CSS uses this approach. Here’s a graphic that illustrates the approach:
DFDL Approach to Expressing Filter Rules
In this approach the logical structure of the input data is described by an XML Schema and filter rules are expressed in annotations in the XML Schema. DFDL uses this approach. Here’s a graphic that illustrates the approach:
QUESTION #1: I think these three approaches are fundamentally different. Do you agree?
QUESTION #2: Are there other approaches which are fundamentally different than the three listed above?
Let’s now look at the advantages and disadvantages of each approach.
XSLT Approach to Expressing Filter Rules
Advantages
- Global (birds’ eye, top-down) perspective on the data. Consider this filter rule: fuzz the latitude/longitude data in the iPhone so that the person’s location is known only to within a 15-mile radius. Such a filter rule requires changes to both the latitude and the longitude data items; they cannot be changed individually, in isolation. This means that a higher-level view of the data is needed.
- No need to add unique identifiers to the data items in the input.
Disadvantages
- Requiring a navigation/path language means there are more things to learn. Not only must users learn the language for expressing filter rules, but they must also learn the navigation/path language. For users who are experts in the domain but not language experts, this might be a step too high.
CSS Approach to Expressing Filter Rules
Advantages
- No navigation/path language needed.
- Simple. Good for domain experts who are not language experts.
Disadvantages
- Must add unique identifiers to the data items in the input. Uniquely identifying each data item in the input might not be possible.
- Local/narrow view of the data.
DFDL Approach to Expressing Filter Rules
Advantages
- No navigation/path language needed.
- No need to add unique identifiers to the data items in the input.
Disadvantages
- An XML Schema must be constructed to describe the input data and users need to understand the XML Schema to know where to place the filter rules. For users who are experts in the domain but not language experts, this might be a step too high.
- Local/narrow view of the data.
QUESTION #3: Have I missed any advantages/disadvantages?
/Roger