|
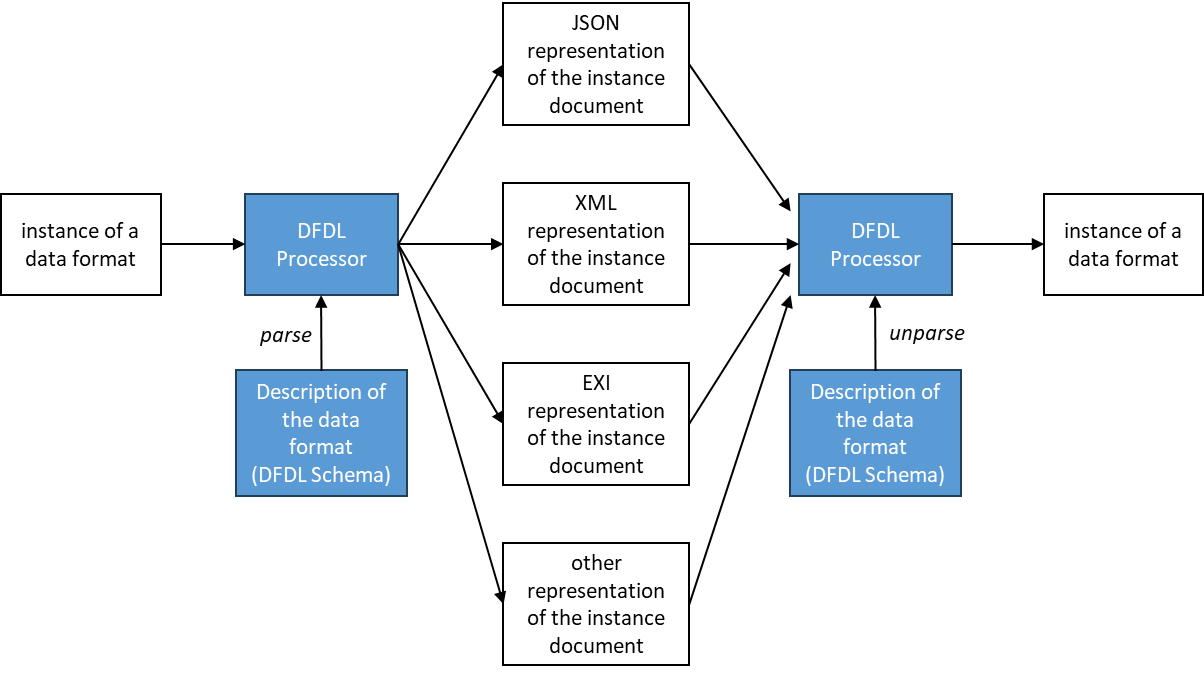
Hi Folks, DFDL = Data Format Description Language The idea behind DFDL is to describe a data format using a formal language (the DFDL language). That description is handed off to a tool (a DFDL processor) which understands the DFDL language. Also, an instance
of the data format is provided to the DFDL processor. The DFDL processor uses the description to figure out how to parse the instance document. The DFDL processor creates an in-memory representation of the instance document. Then, depending how you configured
the DFDL processor, the in-memory representation is serialized (output) as XML. Or JSON. Or EXI. Or some other form.
The description is declarative. It states
what is the structure of the data format. (Get a data format SME to help you describe the data format.) The description doesn't say
how to parse the data format. The DFDL processor figures out how to parse the data format using the description of its structure.
Plus, the same description that is used to
parse the data format is used to unparse the XML (or JSON or EXI, etc.): data format --> DFDL (parse) --> XML --> DFDL (unparse) --> data format Why parse and unparse? Parsing and unparsing data ensures the data fully complies with the format, which greatly reduces data-borne cyber threats. Here is a graphic of the data chain:
A bunch of data formats have already been described using the DFDL language. Here’s a repository of some of them: https://github.com/orgs/DFDLSchemas /Roger |