Rick Jelliffe wrote:
Ø You only have data because you have software.
Does that mean that data without software is pointless/meaningless/futile?
Does that mean that software should dictate the structure and content of data?
As I see it, there are theories about processing data. For example, there are theories about parsing data. But there doesn’t appear to be theories about the data itself. For example, there is no theory about the data that is input into a parser.
So this seems to be the situation with regard to theories:
To take the parsing example, we have this:
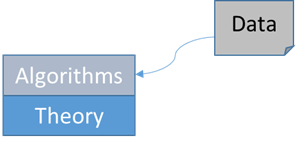
Theory applies to the realm of processing/actions/software. Theory does not apply to the realm of data. Yes?
I am led to these conclusions about developing a data model:
1. First, identify what processing must be done on the data. For example, “Structure the data (a linear sequence of symbols) into a parse tree.”
2. Develop theories and algorithms for that processing. For example, develop theories about grammars and then develop parsing algorithms.
3. Model the data so that it is well-suited to consumption by the algorithms. Algorithms dictate the data model, the data model does not dictate the algorithms. Software/processing/algorithms is primary, data is merely stuff to be gobbled up by the software.
Do you agree?
/Roger