|
Hi Folks, Recall that an XML Schema can reference other schemas, using the include and import elements. And those schemas can then reference other schemas. And so forth. I am writing a description of this. Specifically, I am writing two things: 1. A prose description of traversing all the schemas. 2. An algorithm for how to traverse all the schemas. The prose description must be technically correct, but also understandable by a non-technical person. I made a go at writing these things. See below. Can you think of a better way to write the prose? Do you see any errors in my algorithm?
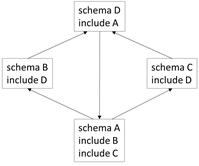
The first thing that I realized is that traversing a schema and its imported/included schemas is a graph-traversal problem! For example, this diagram nicely shows that schemas can form a graph:
See the bottom of this message for the actual schemas. This was a key insight for me, as it means that I can leverage all the graph traversing algorithms that have been developed over the past 50 years. 1. A Prose Description of Traversing all the Schemas
This is the prose description that I initially came up with:
Start with the “main” schema and then follow its include and import elements, recursively gobbling up all schemas. I rejected that. It is terribly ambiguous: What does "gobbling up" mean? What will "recursively" mean to a non-technical person? Then I came up with this description:
The main schema is the initial schema to be examined.
For each schema to be examined, examine its content for include/import elements. The schemas pointed to by each include/import element are then considered schemas to be examined.
If a schema is encountered a second time, it is not examined again. I think that's pretty good. A technical person will notice the massively recursive nature of that description. A non-technical person will probably not realize all that is implied and will simply ignore it. Although I am pretty pleased with that description, I have no doubt that it can be improved. I look forward to your improvements. 2. An Algorithm for how to Traverse all the Schemas
Below is an algorithm for traversing all the schemas. It utilizes two lists: a. ToExamineList: this list contains all the schemas that are currently scheduled to be examined (visited/processed). It is initialized with the "main" schema. b. ExaminedList: this list contains all the schemas that have already been examined (visited/processed). It is initialized to the empty list (i.e., empty set). ToExamineList ← main schema; Do you see any errors in that algorithm? Is there a better (i.e., simpler) algorithm?
XML Schema Example
Above I promised to show the XML Schemas for the example. Here they are: A.xsd
B.xsd
C.xsd
D.xsd
And here is a schema-valid instance document: <A> |