|
Hi Folks, Thank you Michael for alerting me to the inaccuracies in my prose description. Thank you Dimitre for the reference to the algorithms book. Thank you Sam for identifying two bugs in my algorithm.
I made all appropriate fixes. Okay, I have produced three things:
(a) Prose that describes how to traverse all the XML Schema documents.
(b) An algorithm for how to traverse all the XML Schema documents. (c) An implementation of the algorithm.
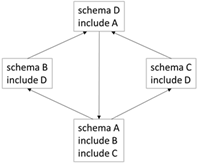
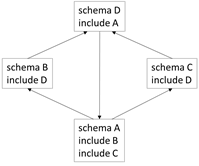
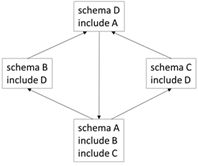
The result of executing the implementation is a list of all the XML Schema documents that can be reached from the "main" XML Schema document. For this schema graph:
The implementation returns this list of schemas: <xs:schema>
... A ... </xs:schema> The remainder of this message contains these things: (a) Prose description (b) Algorithm (c) Implementation (d) Known limitations of the implementation (e) Lessons learned (f) XML Schemas that were used for testing
Traversing an XML Schema Document Graph Recall that an XML Schema document can reference another XML Schema document using the include, import, and redefine elements. And those schema documents can then reference other schema documents. And so forth. Create a specification of this. Specifically, write three things: 1. A prose description of traversing all the schema documents. 2. An algorithm for how to traverse all the schema documents. 3. An implementation of the algorithm using a programming language The prose description must be technically correct, but also understandable by a non-technical person. The first thing to recognize is that traversing a schema document and its imported/included/redefined schema documents is a graph-traversal problem! Here is a diagram that shows how schema documents can form a graph:
See the bottom of this message for the actual schema documents. This is a key insight. It means that we can leverage all the graph traversing algorithms that have been developed over the past 50 years. For instance, see Chapter 5, Graph Traversal, of Steve Skiena's book "Algorithm
Design Manual".
1. A Prose Description of Traversing all the Schemas This is the prose description that was initially crafted:
Start with the “main” schema document and then follow its include, import, and redefine elements, recursively gobbling up all schemas. That was immediately rejected. It is ambiguous: What does "gobbling up" mean? What will "recursively" mean to a non-technical person? Then this description was written:
The main schema document is the initial schema document to be examined.
For each schema document to be examined, examine its content for include/import/redefine elements. The schema documents pointed to by each include/import/redefine element are then considered schema documents to be examined.
If a schema document is encountered a second time, it is not examined again. That's good. A technical person will notice the massively recursive nature of the description. A non-technical person will probably not realize all that is implied and will simply ignore it, but will still have
a good feel for what's going on.
2. An Algorithm for how to Traverse all the Schemas Below is an algorithm for traversing all the schema documents. It utilizes two sets: a. ToExamineSet: this set contains all the schema documents that are currently scheduled to be examined (visited/processed). It is initialized with the "main" schema document. b. ExaminedSet: this set contains all the schema documents that have already been examined (visited/processed). It is initialized to the empty set. ToExamineSet ← {main schema document};
3. An Implementation of the Algorithm The above algorithm was implemented using XSLT 3.0. The new
map feature in XSLT 3.0 is a perfect fit for implementing sets (as you've noticed, sets are important in the algorithm). The result of executing the implementation is a list of all the schema documents that can
be reached from the "main" schema document. For this schema graph:
The implementation returns this list of schemas: <xs:schema>
... A ... </xs:schema> Here is the XSLT code: http://www.xfront.com/traverse-schemas.xsl.txt
Known Limitations of the Implementation The implementation assumes that the XPath
doc() function is always able to access the schema referenced by
@schemaLocation. That might not be the case. It will probably be necessary to also take into account the base location of the schema document.
Lessons Learned A deep understanding of the programming language used to implement an algorithm is essential. Here are several important things to know about using XSLT as the implementation language for this algorithm: - The algorithm calls for a
while loop, but XSLT does not have a
while loop. The workaround in XSLT is to use a user-defined function plus tail recursion. - XSLT has a beautiful function,
generate-id(). Pass to it an XML Schema document and it generates a unique identifier of the schema. Performing set manipulations on that identifier is much easier than performing set manipulations with the schema document itself.
- XSLT has
xsl:sequence and xsl:copy-of statements. Knowing when to use one versus the other is crucial: suppose
generate-id() is applied to schema document
A. Now, suppose
A is stored into a variable via xsl:sequence. Calling
generate-id() will result in the same identifier. But suppose
A is stored into a variable via
xsl:copy-of. Calling generate-id() will result in a different identifier. For this implementation it is crucial that
xsl:sequence be used, not
xsl:copy-of.
XML Schema Example Here are the schemas: A.xsd
B.xsd
C.xsd
D.xsd
And here is a schema-valid instance document: <A> |